
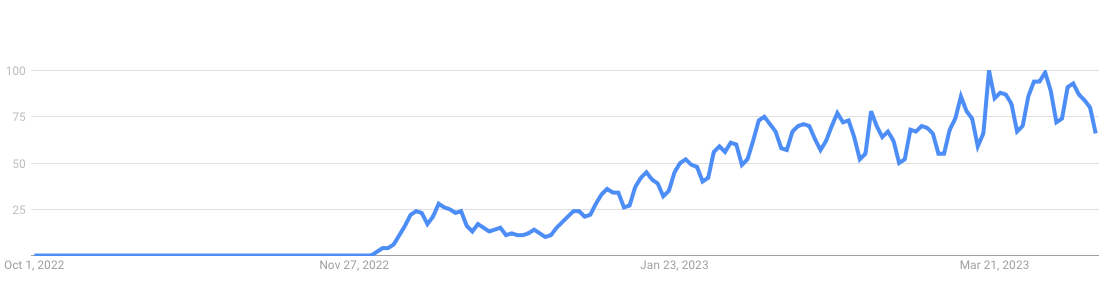
It is not only a hype that probably gets worse before it gets better. And we clearly still are in a hype, as the following chart showing the search interest for ChatGPT between October 1, 2022 and April 12, 2023 from Google Trends shows.
Similarly, the Gartner Group sees Generative AI technology approaching the peak of inflated expectations in its 2022 hype cycle for artificial intelligence.
To be sure, we see only the tip of the iceberg when looking at voice, text or image based services that we all know and use. The Gartner Group also foresees many industrial use cases reaching from drug and chip design to the design of parts to overall solutions.
You think that these scenarios lie far in the future? Read this Nature article from 2021 and think again.

And in contrast to some of the other hypes that we have seen in the past few years, there are actual use cases that support the technology’s survival of the trough of disillusionment. As there are viable use cases, unlike “Metaverse”, Blockchain or NFTs have shown, generative AI is not a solution in search of its problem.
Apart from OpenAI’s GPT and Dalle-E models that surely caught everybody’s attention in the past weeks and months, there are a good number of large language models that are just less known. A brief research that I recently conducted, unearthed more than 50 models that got published over the past few years. For their paper A Survey of Large Language Models that focuses on “review[ing] the recent advances of LLMs by introducing the background, key findings, and mainstream techniques”, a group of AI researchers identified a similarly impressive number of large language models that got developed in the past few years.
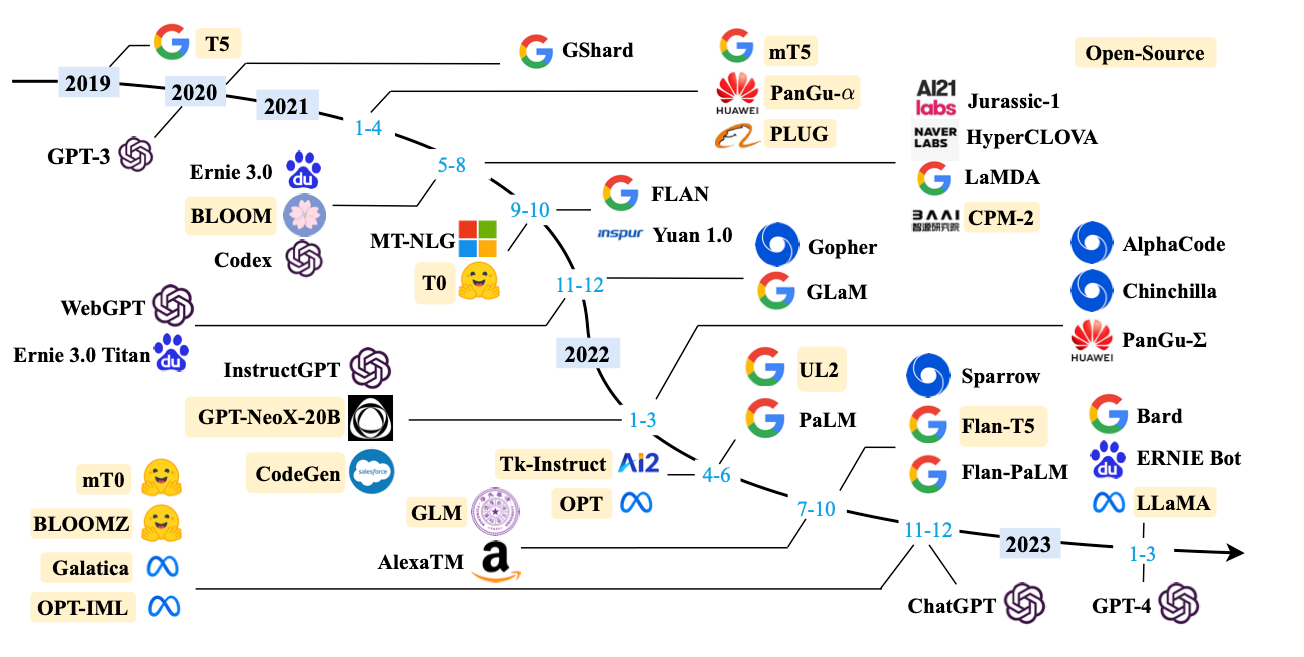
Fig. 1: A timeline of large language models; source: A Survey of Large Language Models
This increased competition, along with research into how the resource consumption of large models can be reduced, e.g. through sparsification, will lead to improved pricing.
Consequently, businesses need to find a way to leverage this technology without harassing their own data security and/or exposing their intellectual property (IP).
That this is easily possible, has been already learned the hard way by companies as diverse as Amazon or Samsung, to name just two better known cases. And then, there are ongoing use cases around the unauthorized use of IP-protected data for training and even many questions around the ownership of generated (derivative?) work products of generative AI, not even speaking in unwanted bias.
The way to be walked involves three major steps:
Education
It is necessary to educate the teams not only on the benefits of using generative AI but also on how to check the output and, importantly, when to not use generative AI. Every employee has a role in keeping the business protected from avoidable mistakes. And no employee wants to make one of those mistakes. Sources that are used for any content that is generated should to be attributed and/or verifiably not be copyrighted. Create some sensitivity about “when in doubt, don’t use it”. Enable your people. For the time being, this training should be frequently reviewed, as the whole area is evolving fast.
Second, it is important to enable personnel to fine tune and then train large language models. This is not necessarily a trivial task that requires some knowledge about machine learning.
Governance
As with most technologies, there is a need for governance to augment the training. Generative AI is a very powerful tool, so it needs to be used responsibly and ethically. To help the employees with their own decision making about when and how it is permissible to use generative AI services in the course of their work, and according to the corporate values, it is necessary to develop, publish and implement a policy that outlines and explains the relevant guidelines to follow.
Points that should be covered by the policy include;
Who is allowed to use generative AI services. Depending on numerous factors like corporate culture, sensitivity of information dealt with, etc. it may be useful to explicitly limit the use of generative AI.
Proprietary or confidential information must not be revealed or disclosed.
Similar to other policies (e.g. use of the Internet in general), there may be a limitation to business use or the permission to also use it for private purposes.
The services should not be used for tasks that are violating any law, regulation, or the company’s code of conduct. This involves discrimination, offensive or hate speech that should be prohibited. This also includes content that is intended to deceive or defraud others.
Whatever the generative AI produces needs to be reviewed.
The use of generative AI to create a work product should be disclosed in order to maintain transparency.
The policy should also include a reference to the offered training that personnel should undertake. Last, but not least, and as bad as it sounds, the consequences of violating the policy must be made clear as well. Here, too, I would concentrate on explanation and rationalizing instead of just wielding a stick.
It might be useful to review this policy frequently, as we are still in a learning period.
Following my own suggestion here: I have used You.com and Google Bard to give me some points that the policy should cover.
Execution
In parallel to this effort, it is time to look for use cases that can meaningfully be implemented. Collect and assess them. Meaningful means that the use cases are important enough to add value and isolated enough to still be able to manage any risks. These use cases can include improving existing capabilities or adding additional ones. What is important is that for all use cases there need to be KPIs that shall get improved and a cost-benefit analysis.
Remember: Not every problem needs to be solved with the help of a LLM! For some problems it is more efficient to use more “traditional” technologies.
At the same time, it is important to be aware of the level of LLM-knowledge that is available in house. This level is, especially in smaller organizations, not too high. The degree of available knowledge is a boundary factor for project execution. So, it is best to start off with a problem that requires only minor fine-tuning of an existing LLM that is powerful enough to to support multiple of the collected use cases. This way, it is possible to learn fast while also getting results fast. Additionally, fine tuning a model comes at far lower cost than fully training a model, as the number of required training cycles is smaller and the amount of necessary training data is far lower. Out of the many available models (see above), one or more will be capable of supporting most of the selected use cases after fine tuning.
The way to success is thinking big while acting small and to walk before starting to run.
Comments
Post a Comment